Where to start when the DB is the bottleneck
Debugging is one of the disciplines any developer should master. Yes, it’s not straight forward as writing code. True, there’s no hard and fast way of doing so. But with proper tools, You will get used to it. It’s even harder to debug when an issue has no functional impact. One such case is performance. For every performance issue, there are two solutions,
- Short-cut - Increase resources
- The right way - Diagnose the issue and fix
You can blindly increase the resources and can get the desired performance in most of the cases. Doing that will solve the problem sometime but not for long.
Recently I had to debug a performance issue related to a service. When I pick up the ticket, initial analysis was already done. Conclusion of it was, database is the bottleneck. There’s nothing much to continue on. At this point service only consumes the writer endpoint of the database for all read and write queries. A suggestion was to separate the load to reader and writer DB endpoints. I guess that could solve the issue. But the real question is why does DB has slowed down? It was a Postgres AWS aurora DB with db.r4.large instance type. And the load was not that high to queue on the DB. According to DB monitoring, some queries even took more than 1 min to resolve. This has propagated to the service and ecs tasks starts to fail due to CPU maxing out.
After going around the problem for some time, I’ve decided to attack the issue in four steps. My target was to reduce the issue little bit so that I can have time to look for a proper solution,
- Check if we can reduce the load
- Go deep into DB query execution and improve
- Separate load to reader and writer
- As final resort increase DB resources
With the initial analysis, I’ve noticed that read queries have the most contribution to the load. So the first target was to find a way to reduce this. We were able to find few places where we fetch data more than we want and immediately push the changes to production, reducing them. Did it work? Yes, it did for 2-3 days. Again on a peak day at peak time, same thing happened.
I had to look for a permanent solution, despite everyone suggesting to go for a larger instance or utilize read replica. In an event like that best tool comes to help is DB query plan analysis.
In order to understand what it is you need to know how a database engine works. It’s not that simple as I’m going to explain but you can separate the process to below steps in that order,
- Parse the query
- Validate
- Optimize the query
- Query Execution
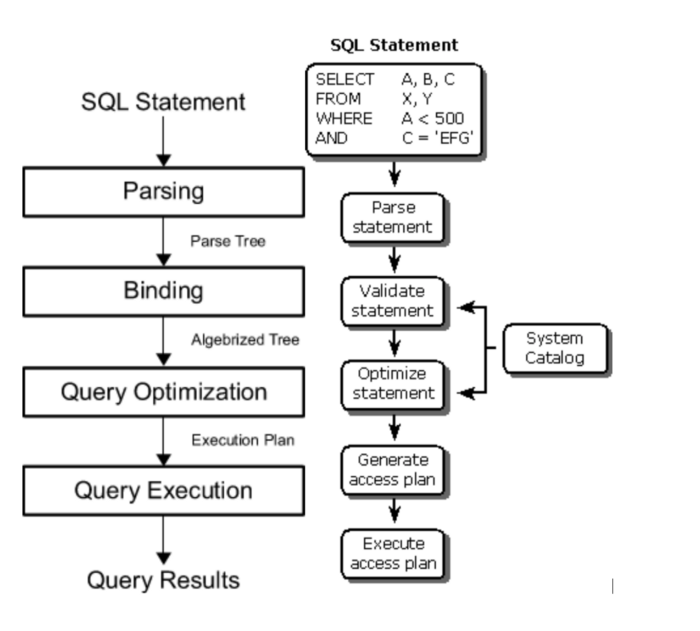
In above process, optimization step is where performance impact lies. Once the query is optimized, RDBMS engine creates a Query plan showing the path of how it will execute the query. Analysing this is the best way to find the bottleneck. Every RDBMS has a command to get the query plan. In Postgres, you can use EXPLAIN ANALYZE to do that.
In a query plan, what you have to look for are,
- Index usage - does the query go through indexes and time took
- Sequential scan - there shouldn’t be any, else no point in using a DB, write to a file :)
- SQL functions causing additional time
- Any step which consumes unnecessary time (find em and look for an alternative path to reduce them)
That’s what I did next and alas it was obvious that a join query does a sequential scan on a table. It only took seconds to create an Index for that column and I could notice more than 400% improvement. Most of you must know this but for those who don’t know, I think this is the best way to handle performance issues related to databases. Lemme just summarize the process as a final note.
- Find if we overuse the database and reduce where it can
- Analyze the queries and find and issues
- If DB size (no of records) is the problem purge historical data (Only real-time data should be in an RDBMS. All the other data should be in a data warehouse if you need them.)
- As final resort, increase DB resources (CPU and Memory)
Hope you had some insight on resolving a Database performance issue yourself. :)
Leave a Comment